API Security - Authentication and Authorization
Massive amounts of data are being transmitted using systems that are not designed for security from the ground up. Even private APIs will sooner or later be broken, exposed, or hacked.
Therefore, a solid API security approach should be designed and implemented with public access in mind and it should involve not only the API itself but also the client applications that use it.
This means that both enterprise and mobile client applications must be treated as first-class citizens when designing an API security solution. In other words, every API client is a potential security threat that, more often than not, is not under our control.
As a consequence, Identity and Access Management (IAM), particularly authentication and authorization, becomes the cornerstone of security. Only when we know who (authentication) is interacting with our API, will we be able to decide which and how (authorization) API operations can be accessed.
For this to be effective, however, API security must be based on a robust stack of battle-tested protocols and standards that can ensure reliability at all levels of the API security infrastructure. These protocols are clearly defined by the Neo-Security Stack:
| AREA | PROTOCOLS |
|---|---|
| Authentication | U2F (FIDO) & Web Crypto |
| Provisioning | SCIM |
| Identities | JSON Identity Suite |
| Federation | OpenID Connect |
| Delegated Access | OAuth 2.0 |
From these protocols, OAuth2 and OpenID Connect deserve a special mention as they are the foundation upon which the others are built.
In this post, we will take a quick look at what these two fundamental protocols have to offer and how they can be used in a real application.
OAuth2
Oauth2 is a scalable protocol for Delegation of Access over HTTPS. It allows a third-party application to obtain limited access to an HTTP service or resource after being granted proper permissions with the resource owner’s consent. The third-party application can then obtain access on behalf of the resource owner or its own.
OAuth2 focuses on development simplicity. That is, authentication itself is provided by an external party. This also applies to federation and authorization. As a consequence, its sole purpose is to provide a set of standard flows to delegate access to client applications. In particular, its goal is to provide a basis upon which other protocols, such as OpenID Connect, can implement access delegation in common scenarios.
Two well-known benefits of using OAuth2 as a foundation to implement access delegation is the prevention of password-sharing between users and third-parties and the ability to revoke access to a specific subset of resources without breaking access to the whole set of resources.
Oauth2 comprises four actors or roles:
- Resource Owner (RO)
- Client
- Authorization Server (AS)
- Resource Server (RS)
The Client is typically the application (enterprise, mobile, etc) making requests to the Resource Server (where the API resides) after being authorized or delegated access to by the Resource Owner (the end-user) using access tokens granted by the Authorization Server on behalf of the Resource Owner.
The following diagram illustrates this flow more clearly:
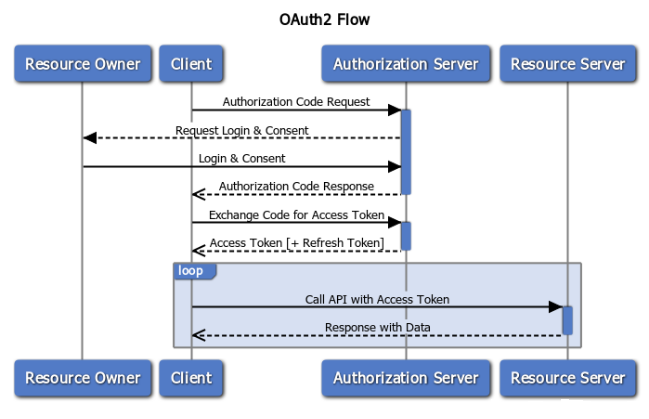
OAuth2 Authorization Flow
The Client Application sends an authorization code request to the Authorization Server to access private information associated with the Resource Owner. Then, the Authorization Server sends a login request to the Resource Owner to get her consent to allow the Client App to access her information. Once the owner’s consent is acquired, the Authorization Server sends the Client an Authorization Code Response which will then be exchanged for an Access Token. With the Access Token, the client can then access the owner’s information using the APIs exposed by the Resource Server.
Depending on the access token’s expiration and Authorization Server configuration, refresh tokens may need to be issued for the Client to continue accessing the owner’s resources.
The permissions or delegated rights granted by the Resource Owner, either if they were explicitly requested by the Client or not, are called scopes. The OAuth specification does not prescribe any type of best practices or guidelines regarding the use of scopes. A few of them, however, are defined by OpenID Connect (see next section).
Depending on the particular implementation of OAuth, tokens can be classified in the following types:
- WS-Security tokens (SAML tokens)
- JSON Web Tokens (JWTs)
- Legacy tokens
- Custom tokens
JWT Tokens, or simply JWTs, are by far the most popular option due to their flexibility. They are the default option in OpenID Connect. They are comparable to SAML tokens in the sense that they are both security tokens that do not depend on any programming language.
JWTs are less expressive than SAML tokens. However, since they are based on JSON instead of XML, they are ideal in low-bandwidth scenarios and to reduce the overhead on systems that process them.
In summary, the main takeaway is to remember that OAuth is a part of a much bigger security approach. It should be used for access delegation only when designing your security infrastructure. As a consequence, when dealing with authentication, authorization, and federation the other components of the Neo-Security stack must be taken into consideration.
We have only touched the mere surface of the OAuth2 specification. More in-depth details can be found here.
OpenID Connect
OpenID Connect (OIDC) is a lightweight identity layer on top of OAuth2 that allows clients to verify the identity of resource owners based on the authentication performed by an authorization server. The purpose of OpenID Connect is to provide federated identity services which are usually provided by an Identity Provider which can be private or public such as Google, Facebook, etc.
The main contribution of OIDC is the ID Token. This is a great improvement over the traditional Access and Refresh tokens provided by OAuth2. ID tokens allow the Client to know details such as types of credentials the user used, authentication timestamps, and any other additional information supported by the OpenID Provider. These pieces of additional information are also known as claims. Put it simply, an ID token is nothing but a JSON Web Token that is used as a way to transmit secure, compact, and self-contained information between parties.
Similarly to OAuth2, OIDC also provides its own set of actors. The table below shows the relationship between both sets:
| OAuth2 | OpenID Connect |
|---|---|
| Client | Relying Party (RP) |
| Authorization Server | OpenID Provider (OP) |
| Resource Owner | End-User |
| User Agent | User Agent |
| Resource Server | Resource Server |
An OIDC implementation offers three types of endpoints: Authorization, Token, and UserInfo. The Authorization Endpoint is defined by OAuth2. It is responsible for authentication and obtaining consent from the user. The Token Endpoint is responsible for the exchange of authorization codes, client identifier, and secrets for Access Tokens. The UserInfo Endpoint is responsible for providing additional user information (claims) that is usually sent along with ID Tokens.
Finally, it is important to remember that OIDC should always be preferred over OAuth2, as it offers a more comprehensive and safer authentication and authorization solution. This article explains the reasons for this in greater detail.
Authentication and Authorization with AWS Cognito
Having explained the benefits of proper authentication and authorization as part of a solid API security approach, it is time to implement a real-world example to see these in action. For this, we will use AWS Cognito due to its flexibility, scalability, and cost-effectiveness. A similar example could be implemented with Google’s Firebase Authentication or Azure Mobile Apps and Active Directory.
AWS Cognito provides authentication, authorization, and user management for web and mobile apps. It does so through two components: User Pools and Identity Pools. User pools are user directories that provide sign-up and sign-in options for your app users. Identity pools enable you to grant your users access to other AWS services. These two services can be used either separately or together.
The diagram below (from the AWS Cognito documentation) shows a sample scenario in which an app tries to authenticate a user, against a User Pool, and then grants this user the corresponding credentials, obtained from an Identity Pool, which are then used to access other AWS services:
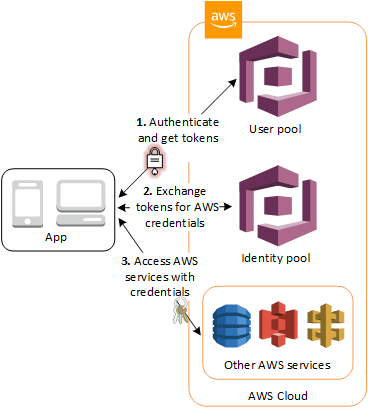
Sample scenario using User Pools and Identity Pools
More details can be found here.
Let’s connect the dots and identify the relationship between OAuth2, OpenID Connect, and AWS Cognito. Cognito provides an Identity Provider through User Pools. But it can also integrate very well with other popular Identity Providers, such as Google and Facebook, employing Identity Pools. In fact, Identity Pools can easily integrate with any other Identity Providers that implement SAML or OAuth2. Due to its support of the OpenID Connect spec, AWS Cognito uses JSON Web Tokens (JWTs) for the OAuth2 Access Tokens, OIDC ID Tokens, and OIDC Refresh Tokens.
To test the functionality provided by AWS Cognito, we will create a simple Lambda function that can be executed only by properly authenticated and authorized users. For demonstration purposes, this function will take a sample JSON document as input and store it in a DynamoDB table. To implement the function’s handler we will use Go.
In summary, the technical specs for our example are presented below:
- Create an AWS Lambda function to store notes on a DynamoDB table. For this, we will use the Serverless Framework
- This Lambda function can be accessed only by properly authenticated and authorized users. For this, an API Gateway should be implemented to provide efficient access control
- Use AWS Cognito to implement user management for our Lambda function through User and Identity Pools
- Access to the API Gateway (and Lambda function) will be controlled by an appropriate IAM role specified in the Identity Pool
To implement our User and Identity pools we could use the Serverless framework. However, for educational and demonstration purposes, we will use Terraform instead.
Lambda Function Handler
The code for our Lambda function handler is presented below:
1package main
2
3import (
4 "bytes"
5 "context"
6 "encoding/json"
7 "os"
8
9 "github.com/aws/aws-lambda-go/events"
10 "github.com/aws/aws-lambda-go/lambda"
11
12 "github.com/aws/aws-sdk-go/aws"
13 "github.com/aws/aws-sdk-go/aws/session"
14 "github.com/aws/aws-sdk-go/service/dynamodb"
15 "github.com/aws/aws-sdk-go/service/dynamodb/dynamodbattribute"
16 "github.com/google/uuid"
17)
18
19// Response is of type APIGatewayProxyResponse since we're leveraging the
20// AWS Lambda Proxy Request functionality (default behavior)
21type Response events.APIGatewayProxyResponse
22
23type note struct {
24 UserID string `json:"userId"`
25 NoteID string `json:"noteId"`
26 Content string `json:"content"`
27}
28
29// Handler is our lambda handler invoked by the `lambda.Start` function call
30func Handler(ctx context.Context, request events.APIGatewayProxyRequest) (Response, error) {
31 var buf bytes.Buffer
32
33 id, err := uuid.NewUUID()
34 if err != nil {
35 return Response{StatusCode: 404}, err
36 }
37
38 cognitoIdentityID := request.RequestContext.Identity.CognitoIdentityID
39 myNote := note {
40 UserID: cognitoIdentityID,
41 NoteID: id.String(),
42 Content: request.Body,
43 }
44
45 dattr, err := dynamodbattribute.MarshalMap(myNote)
46 if(err != nil){
47 return Response{StatusCode: 404}, err
48 }
49
50 svc := dynamodb.New(session.Must(session.NewSession()))
51 input := &dynamodb.PutItemInput{
52 Item: dattr,
53 TableName: aws.String(os.Getenv("tableName")),
54 }
55 _, err = svc.PutItem(input)
56 if err != nil {
57 return Response{StatusCode: 404}, err
58 }
59
60 body, err := json.Marshal(map[string]interface{}{
61 "message": "Note created successfully!",
62 })
63
64 if err != nil {
65 return Response{StatusCode: 404}, err
66 }
67
68 json.HTMLEscape(&buf, body)
69
70 resp := Response{
71 StatusCode: 200,
72 IsBase64Encoded: false,
73 Body: buf.String(),
74 Headers: map[string]string{
75 "Content-Type": "application/json",
76 "X-MyCompany-Func-Reply": "notes-handler",
77 },
78 }
79
80 return resp, nil
81}
82
83func main() {
84 lambda.Start(Handler)
85}
No surprises here! We have a struct to represent a note record. Then, we retrieve the identity ID of the authenticated user, provided by Cognito. Then, we create a note instance using this ID and the note body sent along with the Lambda request. Finally, the note record is sent to the DynamoDB table using the corresponding API.
For the record, this function is for demonstration purposes only. It is intended to be neither complete nor fully correct.
Creation of AWS Resources
Next, we will create the DynamoDB table that the Lambda function will use to store notes. To keep our main file organized, we will create a separate YAML file with the resource description:
1Resources:
2 NotesTable:
3 Type: AWS::DynamoDB::Table
4 Properties:
5 TableName: ${self:custom.tableName}
6 AttributeDefinitions:
7 - AttributeName: userId
8 AttributeType: S
9 - AttributeName: noteId
10 AttributeType: S
11 KeySchema:
12 - AttributeName: userId
13 KeyType: HASH
14 - AttributeName: noteId
15 KeyType: RANGE
16 BillingMode: PAY_PER_REQUESTWith the function’s handler and DynamoDB table properly in place, we will now create the main configuration file for the Lambda function:
1service: aws-lambda-lab
2
3frameworkVersion: ">=1.28.0 <2.0.0"
4
5custom:
6 stage: ${opt:stage, self:provider.stage}
7 # Set the table name here so we can use it while testing locally
8 tableName: ${self:custom.stage}-notes
9 # Set our DynamoDB throughput for prod and all other non-prod stages.
10 tableThroughputs:
11 prod: 5
12 default: 1
13 tableThroughput: ${self:custom.tableThroughputs.${self:custom.stage}, self:custom.tableThroughputs.default}
14
15provider:
16 name: aws
17 runtime: go1.x
18 versionFunctions: false
19 stage: dev
20 region: AWS_REGION
21 iamRoleStatements:
22 - Effect: "Allow"
23 Action:
24 - dynamodb:DescribeTable
25 - dynamodb:Query
26 - dynamodb:Scan
27 - dynamodb:GetItem
28 - dynamodb:PutItem
29 - dynamodb:UpdateItem
30 - dynamodb:DeleteItem
31 Resource:
32 - "Fn::GetAtt": [ NotesTable, Arn ]
33 # you can define service wide environment variables here
34 environment:
35 tableName: ${self:custom.tableName}
36
37package:
38 exclude:
39 - ./**
40 include:
41 - ./bin/**
42
43functions:
44 createNote:
45 handler: bin/createnote
46 events:
47 - http:
48 path: createnote
49 method: post
50 cors: true
51 authorizer: aws_iam
52
53resources:
54 - ${file(resources/dynamodb-table.yml)}Once again, nothing surprising here. First, we specify a few custom parameters for Stage, the name for our DynamoDB table, and some other DB-specific values.
Next, under provider, we specify the details for our Lambda function’s environment. Replace “AWS_REGION” with the appropriate value. One important detail to note here is the IAM roles that the function is going to need. For this specific case, we are going to need access to a few DynamoDB operations.
Finally, we specify the details for the Lambda function itself. This includes the name of the Go file and the API Gateway configuration. For the latter, we simply use a simple HTTP endpoint. An important detail to note here is the authorizer parameter (see the highlighted line above). By setting it to “aws_iam” we are requiring that the caller submit the IAM user’s access keys for it to be authenticated and able to invoke our function.
Streamlining the Build & Deploy Processes
To have our Go code compiled and built every time we deploy a new version of our Lambda function, we will create a Makefile:
1build:
2 dep ensure -v
3 env GOOS=linux go build -ldflags="-s -w" -o bin/createnote createnote/main.go
4
5clean:
6 rm -rf ./bin ./vendor Gopkg.lock
7
8deploy: clean build
9 sls deploy --verbose
With this, we can simply run the following command to have the whole process executed in one step:
$ make deployAnd this is all that is required to have a fully functional Lambda function that sends notes to a DynamoDB table. After deployment, we can check this function and its corresponding API Gateway in the AWS console.
Before we dive into the authentication/authorization section, let’s do a quick test to verify that our function cannot be invoked without proper authentication. For this, we will use API Tester.
First, we need to retrieve the corresponding invoke URL from the API Gateway in the AWS Console. Then, we create a new test by setting the appropriate parameters, the URL, and the corresponding message body.
Creating a new test in API Tester
Once the test is ready, we run it and get the corresponding response:
{"message":"Missing Authentication Token"}As expected, our function failed due to the lack of proper authentication.
Setting Authentication and Authorization for our Function
To get proper authentication and authorization before invoking our Lambda function, we are going to set up a User Pool and an Identity Pool.
The following Terraform script presents the details:
1provider "aws" {
2 region = "<AWS_REGION>"
3 profile = "default"
4}
5
6resource "aws_cognito_user_pool" "notes-user-pool" {
7 name = "notes-user-pool"
8 username_attributes = ["email"]
9 auto_verified_attributes = ["email"]
10}
11
12resource "aws_cognito_user_pool_client" "client" {
13 name = "notes-app"
14
15 user_pool_id = "${aws_cognito_user_pool.notes-user-pool.id}"
16
17 generate_secret = false
18 refresh_token_validity = 30
19 explicit_auth_flows = ["ADMIN_NO_SRP_AUTH"]
20}
21
22resource "aws_cognito_user_pool_domain" "notes-app-jpcedeno" {
23 domain = "notes-app-jpcedeno"
24 user_pool_id = "${aws_cognito_user_pool.notes-user-pool.id}"
25}
26
27resource "aws_cognito_identity_pool" "main" {
28 identity_pool_name = "notes identity pool"
29 allow_unauthenticated_identities = false
30
31 cognito_identity_providers {
32 client_id = "${aws_cognito_user_pool_client.client.id}"
33 provider_name = "${aws_cognito_user_pool.notes-user-pool.endpoint}"
34 server_side_token_check = false
35 }
36}
37
38resource "aws_iam_role" "authenticated" {
39 name = "Cognito_notesAuth_Role"
40
41 assume_role_policy = <<EOF
42{
43 "Version": "2012-10-17",
44 "Statement": [
45 {
46 "Effect": "Allow",
47 "Principal": {
48 "Federated": "cognito-identity.amazonaws.com"
49 },
50 "Action": "sts:AssumeRoleWithWebIdentity",
51 "Condition": {
52 "StringEquals": {
53 "cognito-identity.amazonaws.com:aud": "${aws_cognito_identity_pool.main.id}"
54 }
55 }
56 }
57 ]
58}
59EOF
60}
61
62resource "aws_iam_role_policy" "authenticated" {
63 name = "authenticated_policy"
64 role = "${aws_iam_role.authenticated.id}"
65
66 policy = <<EOF
67{
68 "Version": "2012-10-17",
69 "Statement": [
70 {
71 "Effect": "Allow",
72 "Action": [
73 "mobileanalytics:PutEvents",
74 "cognito-sync:*",
75 "cognito-identity:*"
76 ],
77 "Resource": [
78 "*"
79 ]
80 },
81 {
82 "Effect": "Allow",
83 "Action": [
84 "execute-api:Invoke"
85 ],
86 "Resource": [
87 "arn:aws:execute-api:<AWS_REGION>:*:<API_REST_ID>/*"
88 ]
89 }
90 ]
91}
92EOF
93}
94
95 resource "aws_iam_role" "unauthenticated" {
96 name = "unauth_iam_role"
97 assume_role_policy = <<EOF
98{
99 "Version": "2012-10-17",
100 "Statement": [
101 {
102 "Action": "sts:AssumeRole",
103 "Principal": {
104 "Federated": "cognito-identity.amazonaws.com"
105 },
106 "Effect": "Allow",
107 "Sid": ""
108 }
109 ]
110}
111EOF
112}
113
114 resource "aws_iam_role_policy" "unauthenticated" {
115 name = "web_iam_unauth_role_policy"
116 role = "${aws_iam_role.unauthenticated.id}"
117 policy = <<EOF
118{
119 "Version": "2012-10-17",
120 "Statement": [
121 {
122 "Sid": "",
123 "Action": "*",
124 "Effect": "Deny",
125 "Resource": "*"
126 }
127 ]
128}
129 EOF
130}
131
132resource "aws_cognito_identity_pool_roles_attachment" "main" {
133 identity_pool_id = "${aws_cognito_identity_pool.main.id}"
134
135 roles = {
136 "authenticated" = "${aws_iam_role.authenticated.arn}"
137 "unauthenticated" = "${aws_iam_role.unauthenticated.arn}"
138 }
139}For detailed information about the components described in this configuration follow the links below:
The key points to note here are:
- A User Pool is created to store our users
- A User Pool App Client is created so that it can be referenced by applications creating users
- A User Identity Pool is created to provide temporary AWS credentials (authorization) to properly authenticated users
- An IAM role and its corresponding policy are created to specify that any authenticated user can invoke our Lambda function
It is important to point out that the Resource section of the IAM policy (see line 87, highlighted above) must contain the API ID, as found in the Invoke URL of our API Gateway.
With the authentication and authorization mechanisms properly in place, we are now ready to create a user which we will later use to retest our Lambda function.
Creating and Confirming our First User
To create and confirm a new user against our User Pool, we could create a nice web or mobile app with a rad GUI and proper validations. However, this post is already long enough. So, instead, we are going to use the awesome AWS Cli.
The command to create a user against our User Pool is:
$ aws cognito-idp sign-up \
--region AWS_REGION \
--client-id APP_CLIENT_ID \
--username johndoe@example.com \
--password Passw0rd!Note that AWS_REGION and APP_CLIENT_ID should be replaced with their appropriate values.
The command to confirm this user against our User Pool is:
$ aws cognito-idp admin-confirm-sign-up \
--region AWS_REGION \
--user-pool-id USER_POOL_ID \
--username johndoe@example.comAgain, AWS_REGION and USER_POOL_ID should be replaced with their appropriate values.
Accessing our API with an Authenticated User
To invoke our Lambda function, the following needs to happen:
- Authenticate against our User Pool and acquire a user token
- With the user token, get temporary IAM credentials from our Identity Pool
- Use the IAM credentials to sign our API request with Signature Version 4
Again, to execute all of the above, we could create a nice web or mobile app with a rad interface and proper validations… However, this post is already long enough (even longer now!). So, instead, we are going to use a nice command line tool called The API Gateway CLI tester.
The command to authenticate our new user, get temporary IAM credentials, and invoke our API is:
$ npx aws-api-gateway-cli-test \
--username='johndoe@example.com' \
--password='Passw0rd!' \
--user-pool-id='USER_POOL_ID' \
--app-client-id='APP_CLIENT_ID' \
--cognito-region='AWS_REGION' \
--identity-pool-id='IDENTITY_POOL_ID' \
--invoke-url='API_INVOKE_URL' \
--api-gateway-region='AWS_REGION' \
--path-template='createnote' \
--method='POST' \
--body='{"content":"hello world"}'Once again, replace all the appropriate variable placeholders accordingly.
After running the command above, we should be able to see a new note in our DynamoDB table.
Wrapping Up…
I hope this post helped clarify the importance of authentication and authorization and their role within a solid API security approach. Particularly, it is important to understand the role of OAuth2 and OpenID Connect in modern security frameworks.
Finally, I hope the provided example showed how easy it is to incorporate the benefits of proper authentication and authorization using AWS, Terraform, and the Serverless Framework.
To check the accompanying code for this post go to https://github.com/jpcedenog/blog-api-security-authentication
Thanks for reading!
Image by Thomas Breher from Pixabay